C. E. Berry1, A. Z. Fazilat1, C. Lavin1, H. Lintel1, N. Cole1, S. Stingl1, D. Abbas1, L. E. Kameni1, C. Valencia1, D. C. Wan1 1Stanford University, Plastic And Reconstructive Surgery/Surgery/Stanford University School Of Medicine, Palo Alto, CA, USA
Introduction: With the growing relevance of AI-based patient-facing information, microsurgical-specific online information provided by professional organizations was compared to that of ChatGPT and assessed for accuracy, comprehensiveness, clarity, and readability.
Methods: Plastic and reconstructive surgeons blindly assessed responses to ten microsurgery-related medical questions written either by ASRM or ChatGPT based on accuracy, comprehensiveness, and clarity. Surgeons were asked to choose which source provided the overall highest quality microsurgical patient-facing information. Additionally, 30 individuals with no medical background (ages 18-81, μ=49.8) were asked to determine a preference when blindly comparing materials. Readability scores were calculated, and all numerical scores were analyzed using the following six reliability formulas: Flesch-Kincaid Grade Level, Flesch-Kincaid Readability Ease, Gunning Fog Index, Simple Measure of Gobbledygook (SMOG) Index, Coleman-Liau Index, Linsear Write Formula (LWF), and Automated Readability Index. Statistical analysis of microsurgical-specific online sources was conducted utilizing paired t-tests.
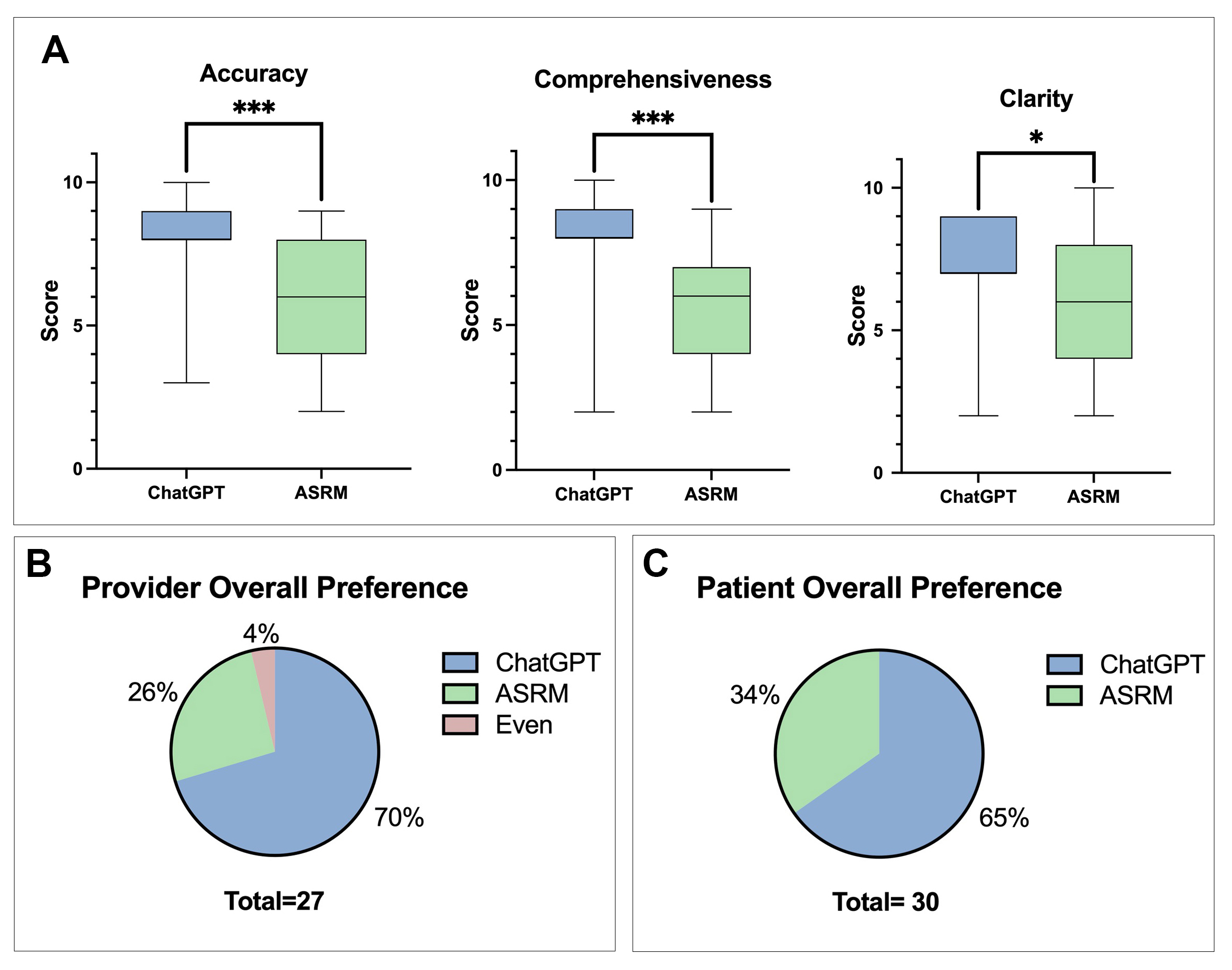
Results: Statistically significant differences in accuracy (p<0.001), comprehensiveness (p<0.001), and clarity (p<0.05) were seen in favor of ChatGPT (Figure 1A). Surgeons, 70.4% of the time, blindly choose ChatGPT as the source that overall provided the highest quality microsurgical patient-facing information. Laymen intended to represent the patient population 55.9% of the time selected AI-generated microsurgical materials as well (Figure 1B). Readability scores for both ChatGPT and ASRM materials were found to exceed recommended levels for patient proficiency across six readability formulas, with AI-based material scored as more complex.
Conclusion: AI-generated patient-facing materials were preferred by surgeons in terms of accuracy, comprehensiveness, and clarity when blindly compared to online material provided by ASRM. Additionally, surgeons and laymen consistently indicated an overall preference for AI-generated material. A readability analysis suggested that both materials sourced from ChatGPT and ASRM surpassed recommended reading levels across six readability scores.